17.让pytroch模型更快速投入生产的方法——torchserve
大纲
- 引入
- 推理过程中的难点
- 如何使推理变快
- TorchServe的优点
- TorchServe技术实现
- 如何部署和运维
- 性能优化方法
- 合作案例分享
详细要点
1. 引入
- 介绍了训练和推理的区别
- 推理需要考虑更多实际场景问题
2. 推理中的难点
- 加载模型和数据需要时间
- 接受不同格式的输入并进行预处理
- 推理速度需要满足实时需求
3. 如何加快推理速度
- 优化模型结构和代码
- 使用动态批量和批量推理
- 编译和优化模型
4. TorchServe优点
- 提供一整套解决方案运行PyTorch模型
- 支持高可扩展性和多进程
5. TorchServe技术实现
- 后端使用Java管理多进程工作
- Python进程负责推理计算
6. 部署与运维
- Docker部署
- 多节点扩展
- 持续优化和监控
7. 性能优化方法
- CPU亲和性
- 预热缓存
- 指标监控
大家好,非常感谢大家的加入。我是马克,在推理和PyTorch方面有着丰富的经验。今天我想和大家谈谈一种让你的模型快速投入生产的方法。训练模型的过程非常艰难,你需要花费大量时间和计算资源。但是推理问题似乎相对简单一些。基本上,你只需要将模型在一个批次上运行即可。这就是推理过程所需要的。然而,如果你更接近真实的场景,可能需要进行一些额外的步骤。比如,你不能每次推理都重新加载模型,而且你可能需要设置一个HTTP服务器,并对其进行推理。然后你需要加载模型权重和相关数据,对于大型模型,这可能需要很长时间。此外,用户不会发送张量给你,他们可能发送文本或图像,所以你可能需要对这些输入进行预处理。然后你就可以运行推理了。
1. Setup an HTTp server
2. Load model weights and artifacts
3. Preprocess inputs
4. Run an inference
5. Make the inference fast
6. Collect performance metrics
7. Deploy on Docker or Kubernetes
8. Scale to multiple workers and machines
然后你就会想,太好了,我想要运行一个推理,但是这个推理要花很长时间。它需要几秒钟的时间。而实时通常不超过10毫秒——这是很多用户对我们推理的期望。所以至少还有一个10倍的乘数在里面。你需要不断地对此进行测量,因为你不能等待用户因为速度太慢而放弃使用你的应用程序。
最终你可能需要将其部署在一种可复现的环境中,比如Docker Kubernetes。一旦你完成了所有这些,那么你还需要处理多进�程的问题。因为你将会有8个GPU,你需要让这八个GPU都保持繁忙。你的CPU有数百个核心,你需要让所有这些核心都保持繁忙。很多时候,我在TorchServe上工作,人们经常问我TorchServe和FastAPI之间的区别,我的回答是,如果你只是做前面其中的四点,FastAPI做得很好,不需要再去使用TorchServe。
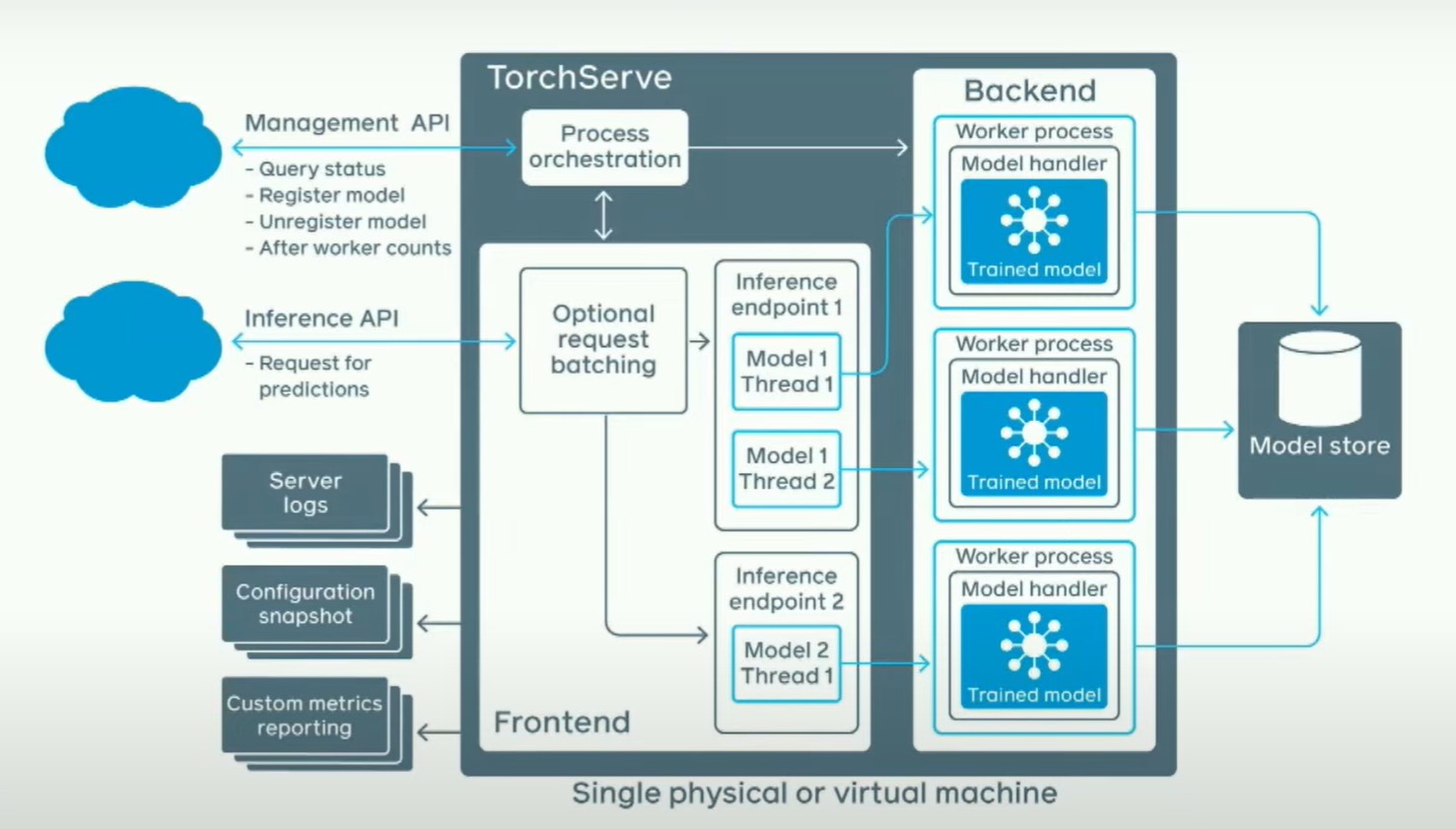
然而,如果你真的担心推断速度的快慢并且想让它在多进程中工作,我们解决了一些比较困难的问题。基本上,我们有一个管理API,在这里你可以说,我想加载这些模型;一个推断API,在这里你可以说,嘿,我想对这个模型进行请求。这将启动几个后端工作器,这些后端工作器实际上是Python进程。你正在启动Python工作器。堆栈的其余部分大部分是用Java编写的。人们经常问我的一个问题是,Java不是很慢吗?为了回答这个问题,这是一个火焰图。
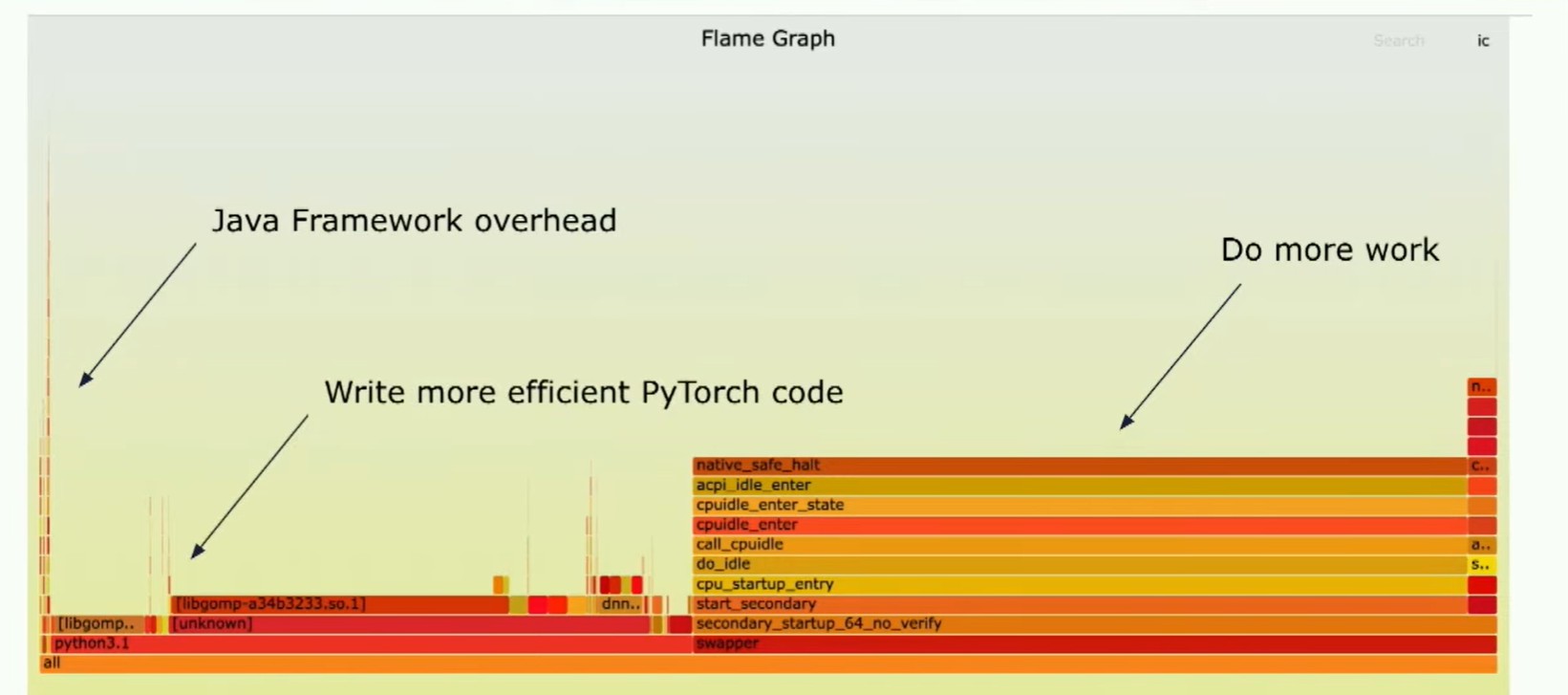
你可以看到这里,基本上你看到了左侧的一条线,那是我们的框架开销。顺便说一下,读这种图的方式是x轴表示的不是时间,而是持续的消耗,因为这是一个采样分析器。所以,这就是Java的开销。还有很多空闲时间,"swapper"的意思是这内核CPU根本不做任何事情。这大约占总运行时间的50%,在我查看的典型客户模型中如此,另外50%的时间花在Python环境中。所以你看这个,你需要做什么呢?首先,你需要做更多的处理,其次,你需要编写更高效的PyTorch代码。让我们谈谈这两件事。
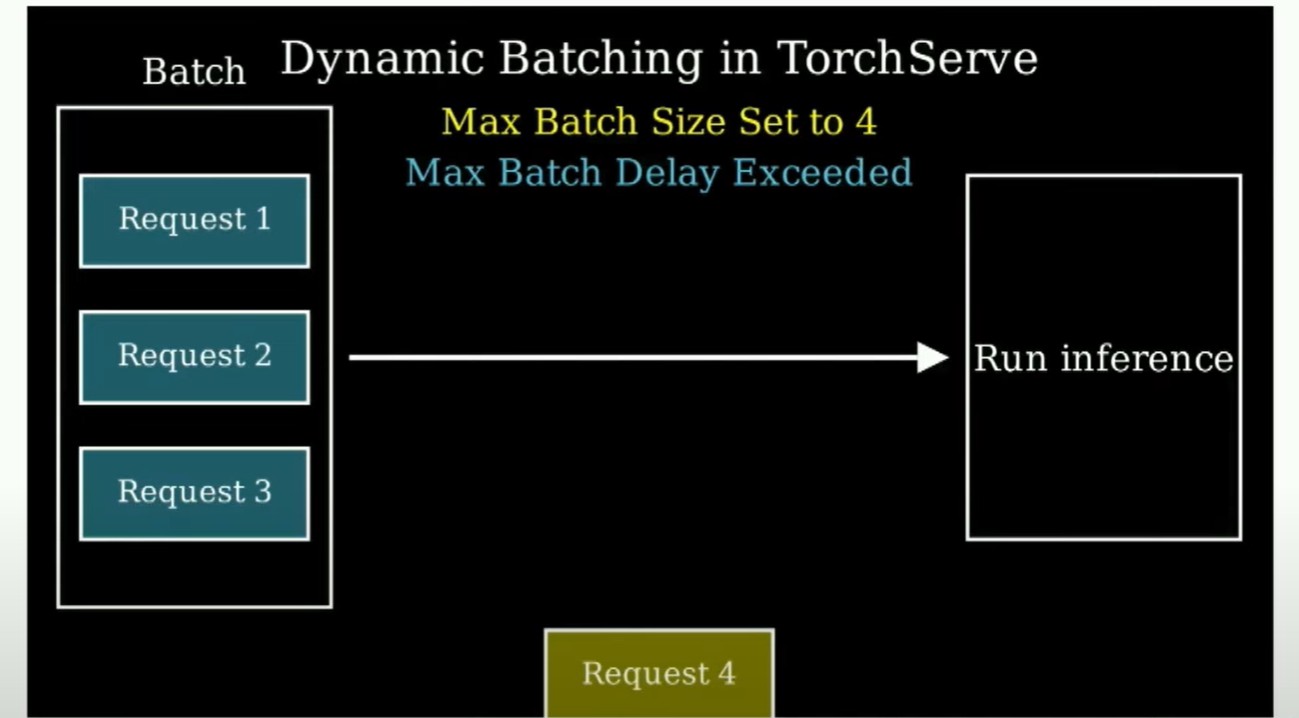
在做更多工作方面,你可用的最重要的优化之一是所谓的动态批处理。动态批处理的本质上是这样的,你说:嘿,我有一个批次大小为4,但我最多等待30毫秒来获取这三个元素。然后当30毫秒过去时,只要有可用的数据,你就把它们组成一个批次(当新的推理请求到达时,它们会被加入到当前正在处理的批次中,而不是单独进行处理)。所以你需要不断让你的机器保持忙碌。

您使用产品的用户体验就像使用Torch服务一样,您需要编写一个被称为处理程序的东西。这个处理程序是一个Python类,基本上需要学会如何预处理您的数据,并将处理后的数据返回。因此,从根本上讲,您希望在纯Python中创建一个推断服务器。这是您需要构建的主要部分。您可以使用类似PDB这样的工具。
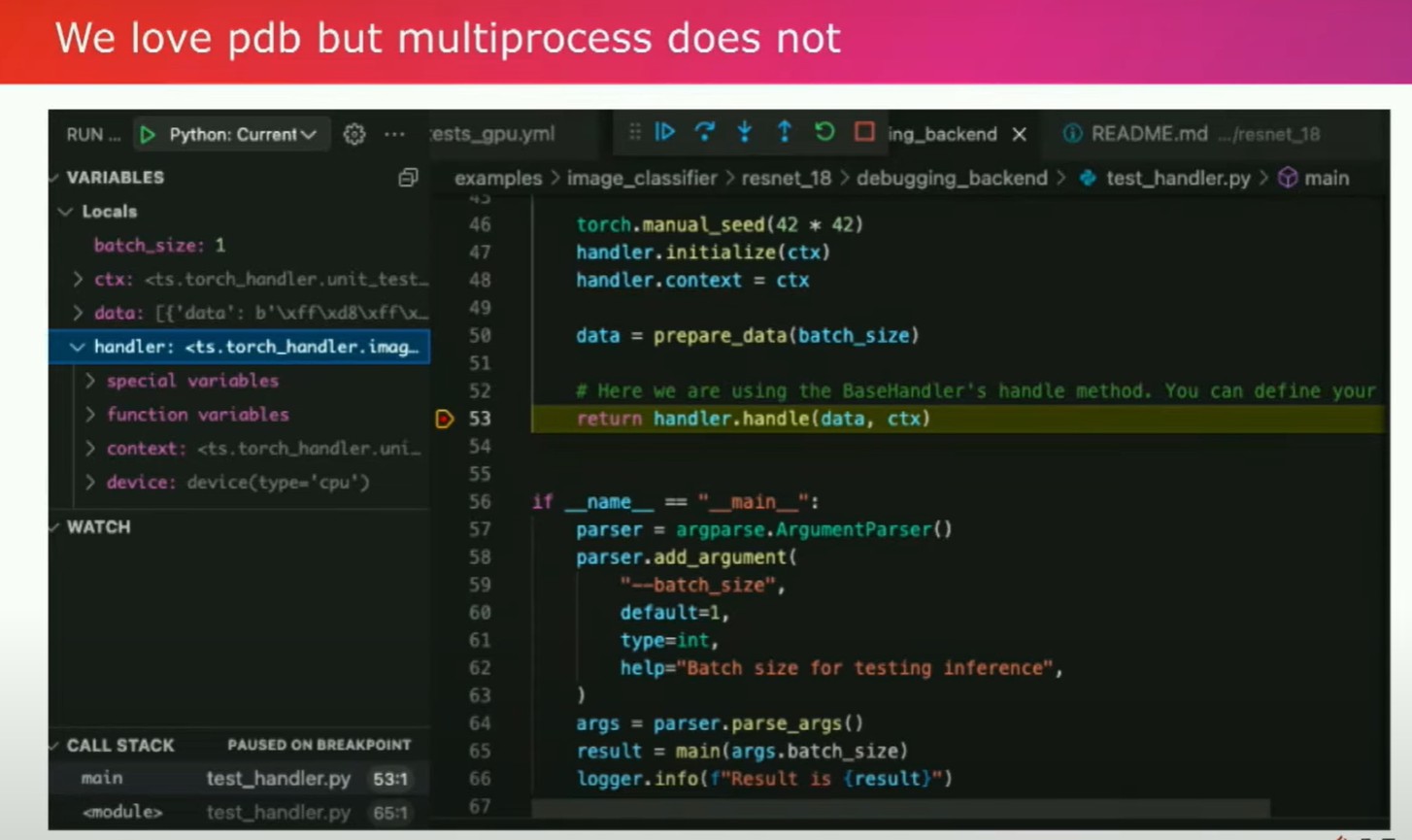
这是我的同事Ankit Gunapal添加的功能。通过这样的方式,您可以轻松地调试程序,找出错误并主动解决崩溃问题。拥有Pythonic的工作流程的好处之一是我们的一些客户,比如Ryan Avery觉得我们的迭代速度很快,因为您不需要将模型重写为不同的语言来进行交互。您可以使用同样的工具进行本地开发和生产部署。

所以,正如我之前提到的,典型程序的一半时间都在一个慢的PyTorch程序中度过。一种非常有用的�调试方法是使用PyTorch分析器。你可以通过设置环境变量来启用它。它的工作原理是显示一个跟踪结果。

在跟踪结果中,你要注意的主要内容是,如果你有类似"stream 7"的标志,那就是你的GPU。(图中的中间)你要注意的一个主要问题是有很多很小的线。这意味着你的GPU在派发独立的核函数,这就意味着没有融合,也就是你没有充分利用你的GPU,相当于你在浪费钱。所以,你要希望那些线是厚厚的条状,而不是这些细小的线。接下来,你可能会问,我的模型很慢,我该怎么办?一种方法是编写一个更小的模型,但也许这个更小的模型并不够好。那么,在不改变模型代码的情况下,你如何减少模型的延迟时间呢?
torch.compile(m, backend="inductor")
torch.compile(m, backend="xla")
torch.compile(m,backend="onnx")
Highly recommended: torch.compile(m,
mode="reduce-overhead"
But JITs have a startup overhead
我一直向人们推荐的主要是Torch编译。你基本上可以使用Torch编译你的模型和感应器。但编译的好处在于它有一个后端参数。例如,如果你想在XLA和TPU上支持Torch服务,我们只需改变一个参数。也许像ONNX对于你正在查看的特定模型有更好的性能特征。所以你可以很容易地进行基准测试和查看。这与pytorch分析器和NVIDIA Insight结合使用,可以帮助你快速找出是什么使得事情变得更快。此外我还推荐了减少开销这种模式。(reduce-overhead)CUDA图表很棒,使一切都变得快速。所以,请使用它们。现在它们终于能够与动态形状一起工作,因此它们与动态批处理很好地配合。这是一件大事,并且最近在2.1版中才支持,所以我极力推荐。
model bt = BetterTransformer.transform(model
NowforGPUandCPU!
另一件事关于模型,目前非常流行的模型是transformers。但是,你不一定需要改变自己的模型去增加更快的核函数。因此,更好的transformer API在神经网络模块级别上工作,可以让你更换更高效的核函数。最好的是,现在这个API可以加速GPU和CPU的工作负载,最新版本是2.1。另外需要记住的一点是,如果你在编译代码,JIT有一定的开销,这是一个无法回避的开销,但是如果你使用更多的缓存,可以大大减轻这个开销。
TORCHINDUCTOR CACHE DIR
TORCHINDUCTOR FX GRAPH CACHE
Make sure to copy these over to reduce
your warm start times
在像TorchServe这样的推断框架中,你将会生成多个Python进程,所有这些进程都可以共享同一个缓存,因为推断是一种尴尬的并行任务。只要你在系统中设置这两个环境变量,甚至可以将它们复制到多个节点上。这将大大减少您的热启动时间。所以我强烈建议您这样做。只需在Docker命令或其他地方复制即可,没有什么花哨的东西。
with torch.device("meta")
model = Llama2
ckpt = torch.load(ckpt, mmap=True)
model.load_state_dict(ckpt, assign=True)
另一件事是在TorchServe中,我们过去推荐人们对模型进行压缩和解压缩,因为它可以成为一个独立的工件。不幸的是,压缩LLAMA7B大约需要24分钟,解压缩需要大约三分钟,这是不可接受的。所以我们不再建议您进行压缩。只需直接使用文件夹即可。然后,在加载实际的权重时,将元设备初始化与MMAP加载结合使用,可以大大加快模型的运行速度,在LLAMA7B上可能快约10倍。这基本上应该成为默认设置。
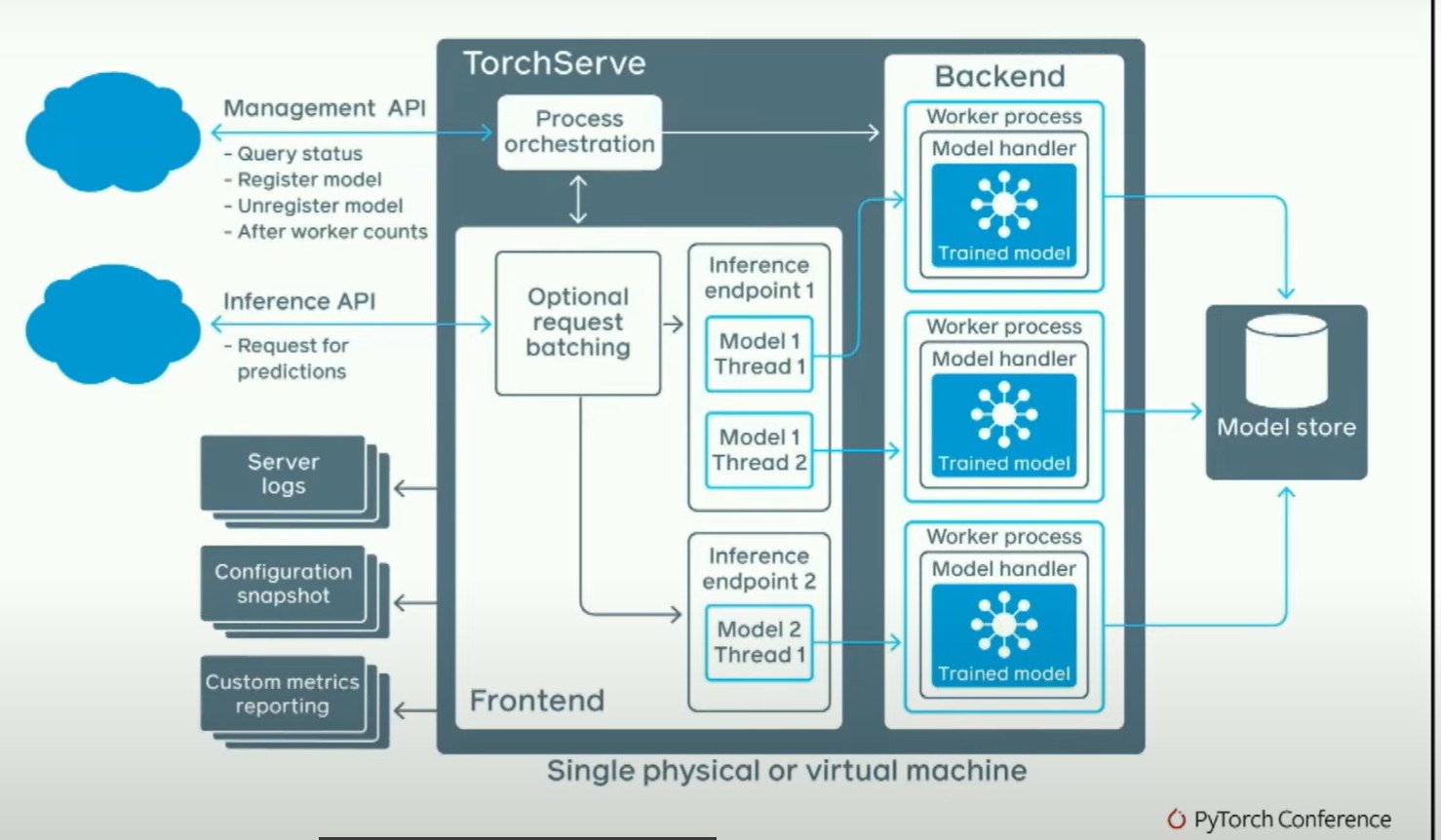
我们架构的一个很酷的地方是,我们可以随意生成任意的后端工作进程,这些工作进程甚至不需要是Python进程。
Model handler can be in any language!
#include<difcn.h>
handle = dlopen("aot.so", RTLD NOW)
所以,例如,像我的同行Matias、Resso和Li Ning一样,一直在致力于为对延迟极为敏感的人们创建C++进程。另外一件事是,当你从单个Python进程转向多个进程时,性能会大幅下降。因此,我设置了一个称为魔法配置的配置变量,将线程数设置为1,很多人可能一直在生产环境中使用这个配置。有一个稍微更好的启发方法,即将物理核心数除以工作线程的数量,这会给你一个稍微更好的结果。通常你能观察到,但问题是,随着核心数量的增加,你会注意到性能并不呈线性增长。所以我非常高兴我们团队有Intel的Minjin Cho加入。

她注意到了一个问题,我们的线程在CPU上的两个插槽间迁移。
因此,如果一个核心正在执行一些工作。然后它会移动到另一个核心,然后又移动回来。所以最终的结果就是你有一个进程,它基本上会不断地丢失缓存,导致性能大幅度下降。我说的是像5到10倍的时间慢下来。
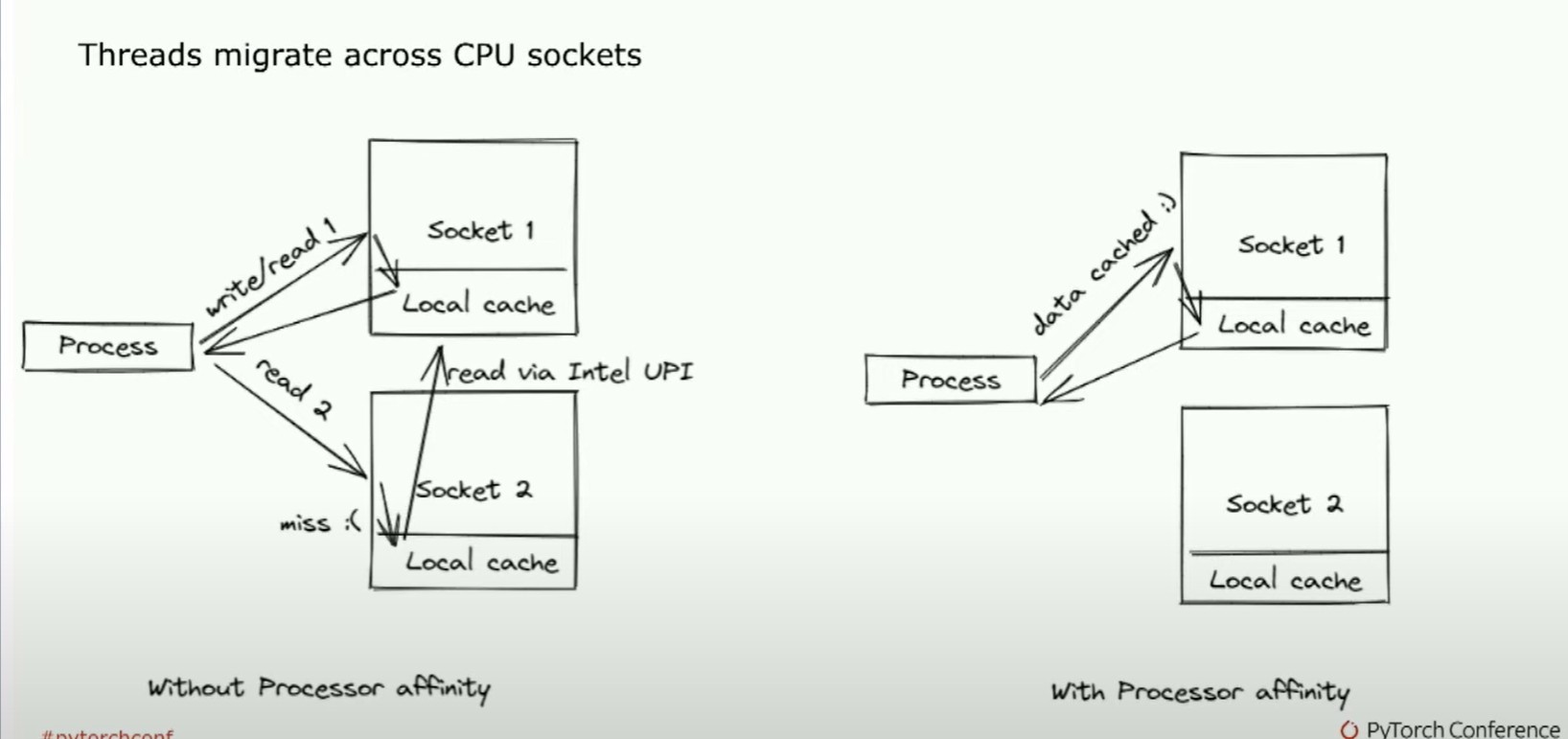
所以关键在于当我们启动Python进程时,我们希望确保它们与特定的进程有一定的关联性。这是我们默认启用并且Torch服务作为一个环境变量所实现的。但你所希望看到的是,有一个忙碌的socket块,而另一个则没有工作。这是HTOP中你希望看到的良好视图,以确保CPU推断是快速的。

这很棒,因为比如Navver就在使用这些优化。他们在博客中提到每年节省了340k,并且通过使用这样的技术,他们的服务器成本也减少了。
Naver:
https://pytorch.org/blog/ml-model-server-re
source-saving/
PyTorch Geometric:
https://pytorch-geometric.readthedocs.io/en/
latest/advanced/cpuaffinity.html
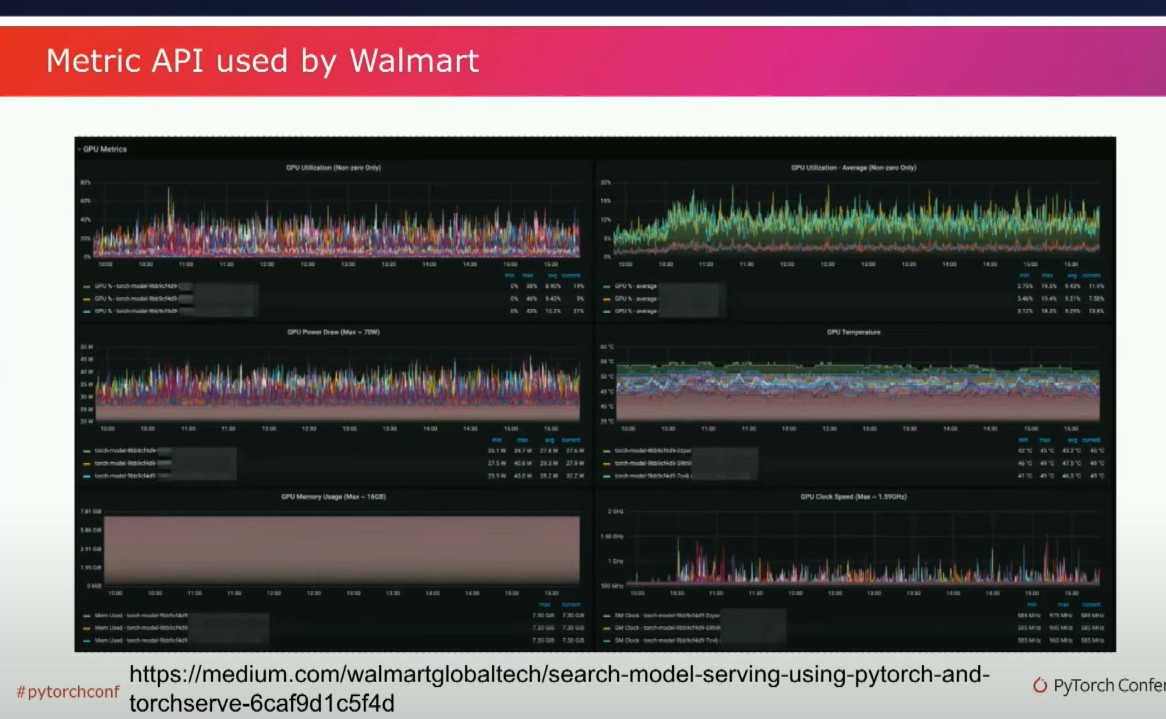
一、你知道的,有一个隐藏的技巧。嗯,PyTorch Geometric也谈到了类似的优化方法应用于他们的GNN工作负载中。所以这是我强烈推荐的一点。我们还讨论了很多关于主动测量模型性能的事情,最近AWS添加了一个新的指标API。你可以在你的Python代码中添加一些仪器,指定这是什么样的指标?是一个计数器吗?是一个量规吗?然后你就可以得到一个看起来很酷的科幻仪表盘。

这是一个来自沃尔玛搜索团队的仪表盘示例,他们一直在使用TorchServe来扩展他们的搜索,并且效果很好。这很酷,因为沃尔玛是世界上最大的公司之一,他们是世界上最大的雇主。对于他们来说,使用TorchServe和Python进行扩展工作真的很不错。
我很高兴地看到TorchServe运行得非常顺利。所以,现在来做一个总结,我感到很幸运的是,TorchServe现在成为了SageMaker、Vertex、MLflow和Kubeflow这些平台上服务PyTorch模型的默认方法。它已经成功地为沃尔玛、Navver和亚马逊广告等工作负载提供服务。虽然我站在这里讲演,但这真的是META、AWS和最近的英特尔团队之间的众多优秀人士的合作成果。谢谢。